Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 10th May 2020, 06:56
10th May 2020, 06:56
|
#961 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
@tormento:
"ABBASSO I GLADIATORS" is not changed here... wrong language or something in your dictionaries? Also, I'm not sure what you mean by "at least put Italic on the right side of the character to input during binary compare." - could you make a screenshot? @jlw_4049/Janusz: I also cannot re-create the resize-and-restore-issue in latest beta, but I'll test on a few other computers. jlw_4049, did you check version in Help -> About - also, how do you restore the minimized OCR window? Latest beta: https://github.com/SubtitleEdit/subt...leEditBeta.zip Contains some good fixes for rippers: - Bluray sup files could miss some images (where a subtitle would be expanded with more text) - Teletext from .ts/.m2ts/.mts sometimes missed last subtitle |

|

|
|
10th May 2020, 07:04
|
#962 | Link | |
|
Registered User
Join Date: Sep 2018
Posts: 391
|
Quote:
It's been working perfectly other then that. Will report back. Sent from my Pixel 3a using Tapatalk |
|
|
|
|
|
10th May 2020, 11:41
|
#963 | Link | ||
|
Acid fr0g

Join Date: May 2002
Location: Italy
Posts: 2,582
|
Quote:
Code:
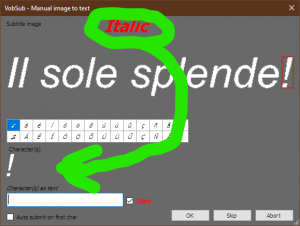
871 01:00:00,263 --> 01:00:02,849 <i>Ripeto. I sospetti del Nite Owl sono scappati.</i> 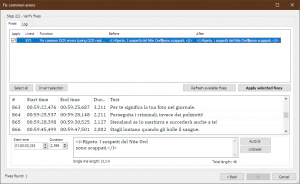 Here is the srt. Fresh install. The OCR files are the ones you distribute. Quote:
__________________
@turment on Telegram |
||
|
|
|
|
12th May 2020, 18:08
|
#964 | Link |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,582
|
It would be nice, when aborting OCR recognition, not to cancel the text of the current paragraph, but let it until the unrecognized character.
Sometimes it happens that some strange symbol can't be corrected by simply expanding and I have to abort to enter it manually. Unfortunately I have to enter the whole text!
__________________
@turment on Telegram |
|
|
|
|
12th May 2020, 22:15
|
#965 | Link |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
If we are already talking about it there is some inconsistency in the window operation
<Import/OCR Blu-ray (.sup)...> without consideration to the Selected OCR method. Maybe someone so wanted so yes it works, but:
Finally: There is an error in Polish translation to the program in line 2528: Code:
is: <Skip>P&omoń</Skip> to be: <Skip>P&omiń</Skip>
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 12th May 2020 at 22:27. |
|
|
|
|
13th May 2020, 11:28
|
#966 | Link | |
|
Registered User

Join Date: Jan 2014
Location: Poland
Posts: 64
|
Quote:
<AutoSubmitOnFirstChar>Autom. proponuj &amp;pierwszy znak</AutoSubmitOnFirstChar> <AutoSubmitOnFirstChar>Autom. proponuj pierwszy znak</AutoSubmitOnFirstChar> borifax 
|
|
|
|
|
|
13th May 2020, 14:51
|
#967 | Link | |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Quote:
Also, "Skip" in the OCR char window will now only skip from current character (and not the whole line). @Melan/Janusz: thx - updated Polish translation. (the "&" string will cause the following letter to be a shortcut - e.g. "&Skip" will react to the "Alt+S" shortcut). |
|
|
|
|
|
14th May 2020, 14:36
|
#968 | Link |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Note: Applies to version 3.5.15 NEXT, beta 92.
Thank you for this change, Nikse555. Error creating <Unknow words> list. Lines # 40, # 73 and # 81 - we have the word FBl there, and it has to be FBI. I have already added the word FBI to the dictionary "names.xml" once. By <Add pair to OCR replace list> I add FBl to FBI. I start OCR and I have it: In the <Subtitle text> window you can see that the conversion has been made and the word is known. This confirms the green color for this line. Only that in <Unknown words> still hangs line # 40: FBl, although without # 73 and # 81. Adding more word pairs works correctly - they do not appear again in the list. Well, unless there is no new word in the dictionary. Line # 40 in this particular case will disappear only when I close the <Import / OCR Blu-ray ...> window and start the whole OCR process again. But then another line with a different word will be the first forever with us until the window is closed. I also checked it for words added to the dictionary - the first line displayed with the unknown word does not disappear. Edition 1
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 15th May 2020 at 11:44. |
|
|
|
|
14th May 2020, 15:12
|
#969 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,582
|
Quote:
__________________
@turment on Telegram |
|
|
|
|
|
16th May 2020, 20:49
|
#970 | Link | |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Latest beta has new (and hopefully improved) detection of space between italic letters: https://github.com/SubtitleEdit/subt...leEditBeta.zip
Do let me know how it works! (it uses the value from "Set un-italic factor" in the list view context menu - probably normally between 0.22-0.32) @tormento: thx for the test .sup files  Quote:
@Janusz: I've fixed an issue related to your last post, but it's really hard to test without your exact setup/sup... could you make a .zip archive with all relevant files, if latest beta still has issues? Last edited by Nikse555; 16th May 2020 at 20:50. Reason: typo+fixes |
|
|
|
|
|
16th May 2020, 23:22
|
#971 | Link |
|
Registered User
Join Date: Jun 2006
Posts: 353
|
When performing OCR it is unable to add a proper match for the percent sign (https://mir.cr/10PHMJUD, # 68): SE recognizes its first part as "o". To add a better match, I deleted this "o" from the DB and run OCR again. This time the first part was recognized as "O", and 'Delete' button is inactive.
__________________
Windows 8.1 x64 Magically yours Raistlin |
|
|
|
|
17th May 2020, 06:41
|
#973 | Link | ||
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Quote:
To fix "%" double click in the list view in main OCR window, then right-click in the list box in the "Inspect" windows and choose "Add better multi match", then expand the images to cover the "%" sign:  Quote:
|
||
|
|
|
|
17th May 2020, 08:25
|
#974 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Shortcuts for the "OCR Character" window is:
 Expand selection: Alt + arrow right Shrink selection: Alt + arrow left Toggle italic: Ctrl+I (+ Alt+I depending on translation) Toggle auto-submit-first-char: Alt+F (depending on translation) Skip current letter(s): Esc (+ Alt+S depending on translation) Skip entire subtitle: Ctrl+Shift+S (new shortcut) |
|
|
|
|
17th May 2020, 11:37
|
#975 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,582
|
Quote:
|←|expand|→| |→|shrink|←| or the same changing function with SHIFT key would be nice. P.S: The red italic word on the right of the character is great. You could remove the one on top of the window now.
__________________
@turment on Telegram Last edited by tormento; 17th May 2020 at 11:44. |
|
|
|
|
|
17th May 2020, 23:02
|
#977 | Link | |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Quote:
I often set the error rate to zero when starting OCR of a new sub for the first 10-20 lines, in which case I add a lot of single letters, and that's much faster without having to press the "Enter" key or the "OK" button. (you need to turn it off again, if the prompt is for a multi letter image, like "ft") |
|
|
|
|
|
17th May 2020, 23:11
|
#978 | Link |
|
Registered User
Join Date: Jun 2006
Posts: 353
|
Nikse555
Thanks. I'd say it is needed to add a brief explanation for this option to the UI, as long as for "add better multi match", as these options' names aren't self-explanatory.
__________________
Windows 8.1 x64 Magically yours Raistlin |
|
|
|
|
17th May 2020, 23:25
|
#979 | Link | |
|
Registered User
Join Date: Jun 2006
Posts: 353
|
Quote:
 UPD: It seems that I didn't enter "%" to the field. It's worth to check if it isn't empty...
__________________
Windows 8.1 x64 Magically yours Raistlin Last edited by GCRaistlin; 17th May 2020 at 23:30. |
|
|
|
|
|
17th May 2020, 23:47
|
#980 | Link |
|
Registered User
Join Date: Jun 2006
Posts: 353
|
Bug(s):
__________________
Windows 8.1 x64 Magically yours Raistlin Last edited by GCRaistlin; 18th May 2020 at 10:07. |
|
|
|
 |
|
|


 Linear Mode
Linear Mode

