Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 4th December 2020, 18:46
4th December 2020, 18:46
|
#61 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Quote:
Here is simple testing of sort of 'point spread function' of resizer: For given 1-sample image buffer:  Code:
LoadPlugin("avsresize.dll")
ImageReader("1sample_230.bmp")
ConvertToYV12()
z_ConvertFormat(width*10,height*10, resample_filter="lanczos", filter_param_a=10)
 And 'true-2D' jinc upsizer gives ideal round response - isotropic for V and H axes as well as with any angled direction. 
Last edited by DTL; 4th December 2020 at 19:55. |
|

|

|
|
4th December 2020, 18:54
|
#62 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Quote:
It is different but 'linear mathematics' resizer I think instead of 'non-linear' like NNEDI and many others. It is some step further to 2D space from simple Sinc (that is really spherical Bessel J0 function as I see in the wiki). The resampler in Jinc is much slower in compare with V+H processing but Jinc (Bessel J1) decays/fades significally faster in compare with Sinc so we will need less taps - may be up to 5..10 will be very good. For upsampling may be weighting the edge of kernel also required as done in SincLin2 kernel to fix computational errors at the end of kernel that are still visible now. It required additional testing. Last edited by DTL; 4th December 2020 at 20:02. |
|
|
|
|
|
4th December 2020, 19:43
|
#63 | Link |
|
Registered User
Join Date: Oct 2002
Location: France
Posts: 2,316
|
Code:
if (args[src_left_idx + 0].Defined())
out_args->add(args[src_left_idx + 0], "src_left");
if (args[src_left_idx + 1].Defined())
out_args->add(args[src_left_idx + 1], "src_top");
if (args[src_left_idx + 2].Defined())
out_args->add(args[src_left_idx + 2], "src_width");
if (args[src_left_idx + 3].Defined())
out_args->add(args[src_left_idx + 3], "src_height");
if (args[src_left_idx + 0].Defined())
out_args->add(args[src_left_idx + 4], "quant_x");
if (args[src_left_idx + 1].Defined())
out_args->add(args[src_left_idx + 5], "quant_y");
__________________
My github. |
|
|
|
|
7th December 2020, 07:27
|
#66 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
One possible speed-up of 2D-convolution with typical 8 or even 10 bit unsigned integer input data: To make not kernel_x_input+output_sum but LUT addition to output sum.
But I do not know is there significant difference with todays CPUs in Mul+Add operation in compare with Add only. It looks only implementation and testing required. Because for 2D convolution we need to multiply each kernel sample with each input sample but all possible 8bit input samples are only 256 numbers limited count - we can make pre-multiplied 256_x_kernel_size LUT and just read-index this LUT instead or Mul. For even 10 taps 2D-kernel we have 20x20x4byte_float_x_256=about 400 kbyte LUT that is good cacheable on most CPUs in season of 201x years and may be later. So the main computational line of convolution (from C-routine) result += src_ptr[lx] * coeff_ptr[lx]; may be replaced with something like result += LUT[src_ptr[lx]]; //- no multiplication - just cache read and addition The LUT start pointer is valid for all line of kernel so it may be calculated once per summing of full kernel line if using SIMD ASM processing. Addition: I think there may be 2 significally different approaches for 2D convolution. They give same output result but may be very different in speed on different platforms: 1. Each output sample got kernel-weighted and input-area covered by kernel_size (filter size/support size) sum. 2. Each input sample 'casts' (add) kernel weighted by input sample to output buffer. The 1. needs significant memory-read traffic (to both input buffer and kernel buffer) and produces very small output write traffic to memory (write once - may be uncached). Kernel buffer is read-only and can be easily shared between all cores in multi-core processing. Input memory buffer is also read-only and cached memory image may be shared by many cores proceses neibour input samples. For LUT using I still not understand if it can be used in this approach. The 2. produces very small read memory traffic for input buffer and produces read_(mul+)add_write traffic for output buffer. If this traffic is good cashed - the actual memory writes depends on CPU memory manager. This approach allows to use LUT for weighting by small number of input variants kernel buffer. But for multi core processing it mostly require each core process far enough input and output memory arrays because for read_(mul+)add_write memory access to output buffer may reqiuire many resources to keep cache coherence between cores. Also this approach allows for easy skip zero input samples processing with simple compare_and_continue. Because zero input sample makes all-zero kernel addition to output buffer and do not changes it. May it good to test both approaches on todays hardware platforms to compare its processing speed. As I see from C-resampler subroutine it uses 1. approach: Code:
for (int y = 0; y < dst_height; y++)
{
for (int x = 0; x < dst_width; x++)
{
const T* src_ptr = srcp + meta->start_y * static_cast<int64_t>(src_stride) + meta->start_x;
const float* coeff_ptr = coeff->factor + meta->coeff_meta;
float result = 0.f;
for (int ly = 0; ly < coeff->filter_size; ly++)
{
for (int lx = 0; lx < coeff->filter_size; lx++)
{
result += src_ptr[lx] * coeff_ptr[lx];
}
coeff_ptr += coeff->coeff_stride;
src_ptr += src_stride;
}
if (!(std::is_same_v<T, float>))
dstp[x] = static_cast<T>(lrintf(clamp(result, 0.f, peak)));
else
dstp[x] = result;
Last edited by DTL; 7th December 2020 at 19:41. |
|
|
|
|
9th December 2020, 17:53
|
#67 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Having tests today with different kernels. It looks easy way to enter different kernels into short void Lut::InitLut(int lut_size, double radius, double blur) function.
So I temporary use 'blur' variable as control variable for different kernels in the range 0..10. And also for switching from jinc-kernel (upsizing) to other kernels (downsizing). Just remove (comment-out) its conversion to 1..0.9 range in the function JincResize::JincResize - // blur = 1.0 - blur / 100.0;. So is my tests: Code:
{
auto radius2 = radius * radius;
auto blur2 = blur * blur;
for (auto i = 0; i < lut_size; ++i)
{
auto t2 = i / (lut_size - 1.0);
if (blur == 0.0f) // if blur value !=0 - use non-jinc kernel
{
double filter = sample_sqr(jinc_sqr, radius2 * t2, blur2, radius2);
double window = sample_sqr(jinc_sqr, JINC_ZERO_SQR * t2, 1.0, radius2);
lut[i] = filter * window;
}
else
// lut[i] = pow(2.7, -4.0f * blur * radius2 * t2 * t2); // Gauss kernel (aligned in 0..10 blur-param range)
{ // or some sort of SinPow kernel - required more tweaking of many 'magic-numbers'
float value = radius * t2 * M_PI / blur;
if (value < (M_PI / 2)) lut[i] = pow(cos(value), 2.2);
else
{
if (value < (M_PI/1.2)) lut[i] = -(cos(value*1.3) * cos(value*1.3)) / (2.5 * value);
else lut[i] = 0;
}
}
}
}
Last edited by DTL; 9th December 2020 at 17:56. |
|
|
|
|
13th December 2020, 08:35
|
#68 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
I remember about OpenMP and tried to use it in the release version 1.1.0. To use it I rewrite a bit convolution subroutines to make 'dst' and 'meta' variables local for each processing row. So it is now compatible with OpenMP at least with main processing routines. The preparation routines still untouched and single threaded.
Current sources and compiled x64 executable with Intel C++ Compiler Version 2021.1 - https://cloud.mail.ru/public/5nwM/2CBA6o3sc libiomp5md.dll is required to load JincResize.dll - taken from Intel C++ Compiler redistributable. Unfortunately the VS2019 can not compile working release build with full optimization enabled. And with partially disabled optimisations it compile very slow executable. Do not know why. Test script: Code:
LoadPlugin("JincResize.dll")
function Ast2(clip c, int isize)
{
return Subtitle(c, "Text",font="Arial",size=isize,x=5,y=20,halo_color=$FF000000, text_color=$00e0e0e0)
}
BlankClip(100,200,180,"RGB24",25,color=$00202020)
Animate(last, 0,100,"Ast2", 35, 180)
AddBorders(150,140,100,100,color=$00202020)
ConvertToYV24()
GaussResize(width/4,height/4,p=15)
JincResize(width*10,height*10,tap=5)
Last edited by DTL; 13th December 2020 at 17:16. |
|
|
|
|
29th December 2020, 08:52
|
#69 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Quote:
The 2D upsizers (for image viewing) better be used with 2D downsizers (for moving pictures content production). But unfortunately old and possibly current motion pictures industry still do not have standard on motion pictures production downsizer (like digital video camera data source and all other motion picture data source like 3d-render/2d-rasterizer etc). Being inherited from 20-th century partially-digital TV (being digital - sampled on frames in time and on lines in 2d space vertically and analogue inside horizontal lines) it mostly based on 1D digital processing of analogue 1D digital/analogue forms of TV signal. And most tv engineers work in 20 and beginning of 21 century was put in keeping 1D signal in best form in terms of ringing/sharpening. And for 1D processing of 1d video signal (and also 1d audio signal) we have good working Sinc-based workflow and appropriate resizers. Unfortunately with 2d sampled moving pictures data things goes not very nice if just use 1D+1D V+H approach or even 'radius-based 1D' used. As I read from ads at about end of 20 th century and beginning of 21 century there was some commertial products as data-sources for moving pictures workflows used 'elliptical filters' for sampled data production. It was CG product - font rasterizers. I.e. convertors of vector image/object data into 2d sampled form acceptable for broadcast TV. But the producers of broadcast video cameras and 3d-rendering engines for moving pictures keeps its internal processing for data-downsizing in secret. And publicity available international engineers/expert groups for moving pictures data processing documents also do not covers the exact form of downsizer for 'video'. So each 'video content' provider uses whatever it want and I think mostly based on faster and simplier 1d-solutions. It the 'free world of video content rippers / community' directly applicable to this internet forum it also means sad things: Because type of downsizer for low-res video rip (or some other way of producing video data) was not and even still not standartized and even not signaled in metadata of provided content so the content viewing person do not straight and correct way of upscaling for viweing. It can use either 1d or 2d based upsizers or 'non-linear' upsizers at its own taste. Even worse - we still almost do not have any good '2d-production downsizer' for creating low-res rips directly applicable to 2d-viewing-upsizer like this Jinc-resize filter. Because current Jinc in 2D as well as Lanczos in 1D are not applicable for 'conditioned' dowsizing and will produce data causing alising/ringing if attempt to view-upsizing using Jinc or Sinc upsizers. When persons feed unknown-source video content to Jinc-upsizer they definetly may and usually will got alising/ringing artifacts. And attempt of using AR-filtering is just attempt to fix distorted result from not very correct workflow. I make some testbench script for future testing of workflows for moving pictures data. I.e. combinations of production dowsizers and viewing upsizers. It have source of 1-point elementary 'video object' being moved in some directions in 2d-space with size (radius/diameter) changed from almost zero to some visible 2d-circle like 2..3 sampling-steps in raduis/diameter. The moving speed is low enough and object get many non-integer positions in 2d space in relation of 2d sampling grid. The best output result of moving pictures handling workflow is - the full round form of object in any frame of animation. Any 'ghosts/ringing' is not allowed. The only allowed is 1 round form undershoot for better visual sharpness. The raising level after end of undershoot higher that base level (0x20) is treated as starting of ringing and not allowed too. Code:
function SourceObject(clip c, float fArg)
{
xpos_rot = c.width/3+(10*Sin(Pi()*fArg/(50)))
ypos_rot = c.width/3-(10*Cos(Pi()*fArg/(50)))
xpos_diag = c.width*2/3+(10*Sin(Pi()*fArg/(50)))
ypos_diag = c.width*2/3-(10*Sin(Pi()*fArg/(50)))
xpos_h = c.width*2/3+(10*Sin(Pi()*fArg/(50)))
ypos_h = c.width/3
xpos_v = c.width/3
ypos_v = c.width*2/3+(10*Sin(Pi()*fArg/(50)))
ch_size = (Int(fArg/100))+1
xpos_rot_i=Int(xpos_rot)
ypos_rot_i=Int(ypos_rot)
xpos_diag_i=Int(xpos_diag)
ypos_diag_i=Int(ypos_diag)
xpos_h_i=Int(xpos_h)
ypos_h_i=Int(ypos_h)
xpos_v_i=Int(xpos_v)
ypos_v_i=Int(ypos_v)
c=Subtitle(c, CHR($95),font="Arial",size=ch_size,x=xpos_rot_i,y=ypos_rot_i,halo_color=$FF000000, text_color=$00e0e0e0)
c=Subtitle(c, CHR($95),font="Arial",size=ch_size,x=xpos_diag_i,y=ypos_diag_i,halo_color=$FF000000, text_color=$00e0e0e0)
c=Subtitle(c, CHR($95),font="Arial",size=ch_size,x=xpos_h_i,y=ypos_h_i,halo_color=$FF000000, text_color=$00e0e0e0)
c=Subtitle(c, CHR($95),font="Arial",size=ch_size,x=xpos_v_i,y=ypos_v_i,halo_color=$FF000000, text_color=$00e0e0e0)
return c
}
BlankClip(30000,800,800,"RGB24",25,color=$00202020)
Animate(last, 0,30000,"SourceObject", 0, 30000)
ConvertToYV24()
# production-downsizing
#SinPowResizeMT(last,width/10,height/10,p=3.2)
#GaussResizeMT(last,width/10,height/10,p=11)
#LanczosResizeMT(last,width/10,height/10)
# restoring vewing-upsizing
#SincLin2ResizeMT(width*8,height*8,taps=15)
#SincResizeMT(width*8,height*8,taps=15)
#JincResize(width*8,height*8,tap=5)
#Levels(25, 1, 55, 0, 255) # can be used for better viewing of processing errors
The 'ideal non-ringing/non-alizing' both 1d and 2d compatible production downsizer example is GaussResize(last,width/10,height/10,p=11) i.e. p=11 at gauss at current avisynth. But it is very soft. And do not provide 'undershoot' that helps to raise visual sharpness a bit. If trying to make more sharp content at given resolution it easy to got ringing/aliasing. So the task for developer some workflow for limited digital frame size is to use such combination of downsizer+upsizer that gives best possible visual sharpness at limited or system-fixed digital frame size in samples (usually called 'pixels') with limited distortions like aliasing/ringing. Last edited by DTL; 29th December 2020 at 09:27. |
|
|
|
|
|
20th January 2021, 12:49
|
#70 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Quote:
For currently theoretical performance: 2x256 FMA units can give sustained stream of 16 float32 FMAs per clock so 4 core typical 3..4 GHz CPU I think can give FMA processing rate up to 192..256 G-FMAs per second. For upsampling 1920x1080 YV12 frame of about 3e6 input samples with taps=4 kernel to 8K needed about 1024 FMA ops per input sample so about 3 G-FMAs per frame. For 25fps - about 76 G-FMAs per second. Currently with 6 core CPU and about 326 G-FMAs per second theoretical peak performance achieved about 20 fps 1920x1080 YV12 input frame processing. It required about 60 G-FMAs per second. So practical performance looks like about 0.18 of possible peak and there is place for some improvement. May be even about 2x more to 0.5 of peak performance. As I see moving to AVX512-capable core is not still added to FMA performance because it only have same 2x256 bit FMA units. Though at intel IntrinsicsGuide there is strange table for _mm512_fmadd_ps performance: IceLake Throughput 1 CPI SkyLake and Knights Landing Throughput is 0.5 CPI - like real true 2x512 FMA units available. Needs testing. Though Knights Landing was Xeon Phi non-consumer-grade CPUs. From Wiki: Xeon Platinum, Gold 61XX, and Gold 5122 have two AVX-512 FMA units per core. Xeon Gold 51XX (except 5122), Silver, and Bronze have a single AVX-512 FMA unit per core. So looks like still no 2x512 FMA units per core at consumer-grade cores for now. Last edited by DTL; 20th January 2021 at 14:11. |
|
|
|
|
|
1st February 2021, 23:49
|
#71 | Link |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Well - finally some milesone in performance: Function for planar/true-2d upsampling with avx(2?) instructions with multiplier=4 and taps=4 running as single thread and with multithreading frame-based in Avisynth+ reach about 33% of theoretical G-FMAs performance of CPU like i3-9100T and i5-9600K. It allow to upsize FullHD 1920x1080 YV12 frame to 8K with taps=4 with about 45fps at i5-9600K running at 4.3 GHz in 6 threads. The most performance boost in compare with previous AVX FMA 8-samples engine looks like reached because of smaller memory using with 'circulating buf' of size only out_width_x_KernelSize instead of full output frame size in floats. With C-code upsample using of circulating buf makes very small difference may be because of too slow CPU processing without good AVX FMA engine. I think of making multithreaded of the '_cb' functions in the future - I still poor in C++ so need to found how to make array of vectors for each thread. Also some work need for aligning edges of processed frame stripes by each thread. Also some more ideas for future optimizations may add to performance. I made some attempt to release binaries at https://github.com/DTL2020/AviSynth-...tag/v0.3-alpha for testing.
Only x64 builds available because need for all 16 ymm registers for processing. Test script with AVX CPU and Avisynth+: Code:
LoadPlugin("JincResize.dll")
BlankClip(1000, 1920,1080,"YV12")
JincResize(width*4,height*4,tap=4,opt=2,threads=1,ap=2)
Prefetch(_num_cores_)
Last edited by DTL; 2nd February 2021 at 00:04. |
|
|
|
|
6th February 2021, 16:26
|
#73 | Link | |
|
Registered User
Join Date: Jul 2018
Posts: 1,067
|
Quote:
Results combined to 1 image file: https://i1.imageban.ru/out/2021/02/0...03581cfc0a.png 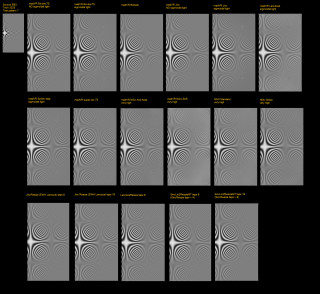 In compare with some slow in processing with high number of taps sinc and jinc it looks EBU engineers live in separate perfect world and not very good connected to real sad world of digital moving pictures content production companies. So most of build-in madVR upsamplers works bad enough on EBU scaler test dataset and mostly designed to fight against ringing on real world badly 'conditioned' digital moving pictures data while trying to keep sharpness as great as possible. Also the last pictures shows significant difference between sinc and jinc upsamplers at this EBU scaler test pattern - jinc filter-out all 'diagonal' frequencies outside 1/sample_step (1D Nyquist limit). Both sinc and jinc with high enough taps values restore vertical and horizontal frequencies good. Looks I need to add ratio 2x with taps 8 AVX-enchanced multi-sample function too. It will fit with ymm AVX registers with about 8 input samples processing without bulk memory load-store operation. |
|
|
|
|
|
22nd December 2022, 05:53
|
#74 | Link |
|
Registered User
Join Date: Jan 2018
Posts: 2,156
|
JincResize 2.1.1
https://github.com/Asd-g/AviSynth-JincResize/releases |
|
|
|
|
23rd December 2022, 12:06
|
#75 | Link |
|
Registered User
Join Date: Jan 2018
Posts: 2,156
|
JincResize 2.1.2
https://github.com/Asd-g/AviSynth-JincResize/releases |
|
|
|
 |
| Thread Tools | Search this Thread |
| Display Modes | |
|
|




 Linear Mode
Linear Mode

