Welcome to Doom9's Forum, THE in-place to be for everyone interested in DVD conversion. Before you start posting please read the forum rules. By posting to this forum you agree to abide by the rules. |
 20th May 2020, 14:35
20th May 2020, 14:35
|
#1001 | Link | |
|
Acid fr0g

Join Date: May 2002
Location: Italy
Posts: 2,563
|
Quote:
__________________
@turment on Telegram |
|

|

|
|
20th May 2020, 14:35
|
#1002 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Quote:
But now I don't have the "error_log.txt" file, the warning window is the same as before.
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 20th May 2020 at 14:47. |
|
|
|
|
|
20th May 2020, 17:46
|
#1004 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
@Janusz: OK, think I got the crash now: https://github.com/SubtitleEdit/subt...leEditBeta.zip
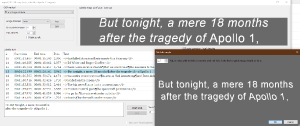
@tormento: Right click on image for line 3 in Apollo13 and choose "Set align angle" (previously "Set un-italic factor"). Looks like "0,21" is a good value. Does that work for you? (#pixels is space=15) Last edited by Nikse555; 20th May 2020 at 17:49. |
|
|
|
|
20th May 2020, 18:02
|
#1005 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Quote:
I have a few more comments for this wonderful program that do not depend on the OCR method chosen, but first I need to prepare the appropriate files.
__________________
Sorry for my mistakes - I'm using a translator. |
|
|
|
|
|
20th May 2020, 18:46
|
#1006 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,563
|
Quote:
__________________
@turment on Telegram |
|
|
|
|
|
20th May 2020, 20:18
|
#1007 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
@tormento: thx
 This should now work (did not work because it was half italic / half regular): https://github.com/SubtitleEdit/subt...leEditBeta.zip This should now work (did not work because it was half italic / half regular): https://github.com/SubtitleEdit/subt...leEditBeta.zipBut it was also working before for me... and for you too, if you had been using the dictionaries included with SE, like "eng_OCRFixReplaceList.xml". Why would you not use them? |
|
|
|
|
21st May 2020, 14:17
|
#1008 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Quote:
For this example I created a sup file from the text "the tragedy ofAlabama" where "the tragedy of" I marked italic. I only installed the following dictionaries: French, German, Italian, English without additional OCRFixReplaceList.xml files. For: French, German, Italian, English - the patch works ok. The text after OCR looks like this: "<i>the tragedy of</i> Alabama", for: Polish and "none" like this: "<i>the tragedy</i> ofAlabama". I did not check others, but I think the amendment should work in all languages because the word "ofAlabama" is not correct in any language, and any division in this case may occur between italics/regular or regular/italics always regardless of the language chosen how many new words exist in the selected dictionary. Example from Poland: "fotografAdam" (photographer Adam).
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 21st May 2020 at 15:01. |
|
|
|
|
|
21st May 2020, 16:50
|
#1009 | Link | |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Quote:
I've added a Polish one based on your input here: https://github.com/SubtitleEdit/subt...eplaceList.xml Feel free to add to it
|
|
|
|
|
|
21st May 2020, 21:57
|
#1010 | Link | ||
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Quote:
Quote:
In the first version of the file, the line contained only one phrase "photographerAdam". "Adam" is only 5 letters, I thought maybe this is it? I have created a new file. I added a few lines and longer words starting with "A". OCR worked, but as you can see above - not quite. The division has happened, but </i> it is not everywhere it should be. Only on line 2 is good. I disabled split after "f" in "pol_OCRFixReplaceList.xml". The effect of this is at the bottom. The division is correct, </i> is where it should be, also on line 1. Conclusion: The rare case of such a combination of words means that we have to choose ourselves: enable or disable this option and when in our "OCRFixReplaceList.xml", because we can do more damage than it is worth. If you really don't have anything to do, you could look into the source, because changing the dictionary repeatedly to any one installed and each time OCR with a new dictionary causes that what now looks so nice at the bottom will look like at the top again. Only starting OCR restores order again. I know that nobody will mix dictionaries under normal use, but the problem is.
__________________
Sorry for my mistakes - I'm using a translator. |
||
|
|
|
|
23rd May 2020, 10:16
|
#1011 | Link | |
|
Acid fr0g
Join Date: May 2002
Location: Italy
Posts: 2,563
|
Quote:
I tend not to use it because the I have trained the OCR so well that I can postprocess I-l after OCR and have a faster job. Perhaps you could implement a OCR fix with OCR errors only and not word dictionary aware.
__________________
@turment on Telegram |
|
|
|
|
|
23rd May 2020, 12:56
|
#1012 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
@Nikse555
To report a mistake. Occurs since beta 119, beta 112 works fine. The previously reported bug in beta 123 and later concerned a missing dictionary. Because I rarely use "Prompt for unknown words" so the option was not enabled and was not checked. In my previous thread I used "Binary image compare" so I didn't notice this error. Today I returned to nOCR. My Settings: for the function to work, the dictionary must be selected so it is selected. "Draw missing texts" - disabled so that the program does not call for every new unknown letter. ( Even for this function of the program it is worth using nOCR )."Prompt for unknown words" - enabled. "Fix OCR errors" - disabled - OCR does not use user files. "Try to guess unknown words" - does not matter with "Fix ..." = disabled. It doesn't work though it's turned on. Start OCR begins to process the text until it encounters the first unknown word. With a well-constructed character base, it will be a word not in the dictionary, otherwise an unrecognized character in the word. The process calls the "Spell check" window. "Skip one", "Skip all", "Abort" causes an error window to be called: Depending on what we choose, we will return to Windows - the program will crash or to the Program. I checked on various sup files, including those available from this forum. @Tormento Quote:
My assumption is that changes made for English should not affect other languages available in the program.
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 23rd May 2020 at 13:34. |
|
|
|
|
|
23rd May 2020, 20:33
|
#1013 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
@Janusz: thx for the crash info
Should hopefully be fixed here: https://github.com/SubtitleEdit/subt...leEditBeta.zip Also, Ctrl+T in the OCR window will start some auto-training... probably not too useful, but it's a little fun to play with. |
|
|
|
|
23rd May 2020, 21:55
|
#1014 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Patch works, thank you.
 Quote:
However, using it did not bring up any additional windows as it does now. Something was happening in the background, the effects of this work could not be seen. I noticed this window yesterday, but I didn't have time to check exactly what it was. I am curious myself how this file will look. 
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 24th May 2020 at 07:28. |
|
|
|
|
|
24th May 2020, 08:58
|
#1015 | Link |
|
Registered User
Join Date: Feb 2004
Location: Mars
Posts: 428
|
Forgot... for training you need a .srt file with spaces around characters, like:
Code:
1 00:00:00,490 --> 00:00:02,350 a b c d e f g h i j k l m n o p q r s t u 2 00:00:02,530 --> 00:00:04,150 v w x y z 3 00:00:04,240 --> 00:00:06,240 0 1 2 3 4 5 6 7 8 9 , . ( ) [ ] ' " $ % ♫ ♪ & 4 00:00:06,510 --> 00:00:08,200 A B C D E F G H I J K L M N O P Q R S T U 5 00:00:08,320 --> 00:00:10,570 V W X Y Z 6 00:00:11,510 --> 00:00:13,510 : ; - ! ? 7 00:00:13,540 --> 00:00:15,540 é É Č Ę Ė Į Ū č ę ė į ų 8 00:00:15,560 --> 00:00:17,560 ß ü Ü æ ø å ä ö Æ Ø Å Ä Ö 9 00:00:17,584 --> 00:00:19,584 ff ft fi fj fl rf rt rv rw ry rt ryt tt TV tw yt yw Also, unattended OCR alarm (taskbar blink/beep) is now customizable (via Settings.xml) and these settings ( in latest beta: https://github.com/SubtitleEdit/subt...leEditBeta.zip ): <UnfocusedAttentionBlinkCount>50</UnfocusedAttentionBlinkCount> <UnfocusedAttentionPlaySoundCount>2</UnfocusedAttentionPlaySoundCount> <UnfocusedAttentionPlaySoundEvery>2</UnfocusedAttentionPlaySoundEvery> |
|
|
|
|
25th May 2020, 11:57
|
#1016 | Link |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
And the game is over.
The text with 6052 lines (31736 words, 189721 characters) was read without the need to add at least 1 character. I used nOCR. I'm really shocked how it worked for the "Arial Black" font. The one thing I've corrected before is that I've added a few triple and a dozen double characters to your train.srt file A great tool.
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 25th May 2020 at 13:10. |
|
|
|
|
25th May 2020, 14:01
|
#1018 | Link | |
|
Registered User
Join Date: Apr 2020
Location: Poland
Posts: 143
|
Quote:
Launch the program. In [OCR Method] you will have a new method: "OCR via nOCR". From the parameter name you can see that not everything can work as it should. And that's how it is now. I didn't take notes of what I was doing and I can't reproduce what I wrote above. Fortunately, I have saved the character base and it can be repeated with it, but I can't generate the same database a second time. --- For sure @Nikse555 will read it so I will add that: the original character base entered from the hand to read the entire file error-free contains 367 elements, the new one was created by N-OCR training 481 characters so it may contain already recognized characters. I don't have the tools to check it. --- It turned out that my admiration turned out to be premature. My mistake - I left my character base in the working directory, thanks to which the generated new characters were added to my base and hence the sensational result. Detriment. It seems that this project is no longer being developed. In the state in which it is now it can only serve as a curiosity. -------------------------------------------------------------------------------------------- @Nikse555 There was a problem with beta 161. - nOCR has stopped recognizing: . , - (three characters) and calls for each character encountered as a new one - unknown. - 'o' recognizes as '0' or 'c', but this does not occur for everyone 'o' in the text. Example: beta 145: Nie. Na United Fusion Corporation. To co innego. (I worked on this version until then). beta 161: Nie* Na United Fusion Corporation* T0 co inneg0*
__________________
Sorry for my mistakes - I'm using a translator. Last edited by Janusz; 27th May 2020 at 07:26. |
|
|
|
|
|
27th May 2020, 17:50
|
#1020 | Link | ||
|
Registered User
Join Date: Jun 2006
Posts: 353
|
Quote:
Quote:
__________________
Windows 8.1 x64 Magically yours Raistlin |
||

|
|
 |
| Thread Tools | Search this Thread |
| Display Modes | |
|
|


")

 Linear Mode
Linear Mode

